
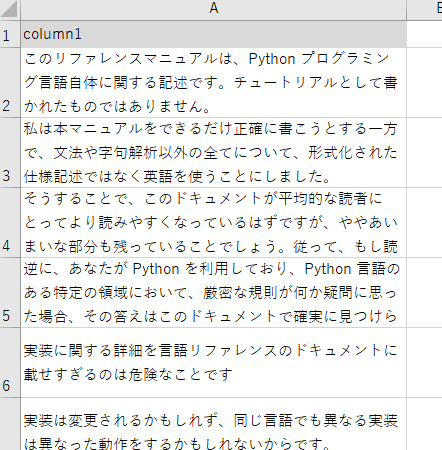
以前英語のWordCloudを作成しましたが、今回は日本語の形態素解析ができるMecabライブラリを使って、以下のエクセルデータから日本語用のWordCloudを作成してみたいと思います。
英語ワードクラウドを作成した記事はこちらです。

Mecabインストール
インストールはこちらの記事を参考にしました。
形態素解析エンジン Mecab をWindowsにインストールする #自然言語処理 – Qiita
以前当ブログでも紹介していたMecabですが、DLしてきたUnidic辞書がうまく動かなかったり、Mecabの設定ファイルが意図したところにDLされておらず、パスの通ったディレクトリに手動で移動させたりで少々やっかいなライブラリだなと改めて感じました…
日本語フォントをダウンロードする
今回使用するmatplotlibは、そのままでは日本語に対応しておらず、実行すると日本語部分が「▯▯▯」と表現されてしまいます。(これを豆腐というらしいです。)このため、日本語に対応したfontをウェブからダウンロードする必要があります。
ダウンロードは以下のサイトにアクセスして行いました。(IPAexゴシックを使用しています)
IPAex フォント Ver.004.01 | 一般社団法人 文字情報技術促進協議会 (moji.or.jp)
ダウンロードしたフォルダにある「ipaexg.ttf」を管理しやすい場所に格納します。今回は実行ファイルのディレクトリに「font」フォルダを作成し、そこに格納しています。
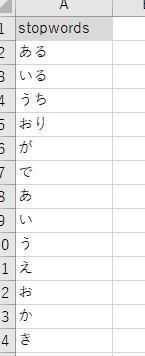
ストップワード(除外キーワード)を設定する
前回英語ワードクラウドを作成した際に使用したnltkライブラリでは、あらかじめ一般的なストップワードが用意されていましたが、既存の日本語用ストップワードであまりベストなものがなさそうだったため今回は地道に手動で作成しました。基本的にはひらがなとカタカナ五十音、句読点などで、その他は出来上がったワードクラウドをみてあとから追加していくといいと思います。
今回はExcelにstopwordシートを作成していて、そこに記載しています。
サンプルコード
全体のサンプルコードです。
import os
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import MeCab
#mecabを初期化
mecab = MeCab.Tagger("-Owakati")
#日本語対応のフォントファイルパス(webからDLしてきたフォントフォルダを実行ファイルディレクトリに格納している)
script_dir = os.path.dirname(os.path.abspath(__file__))
font_path = 'fonts/ipaexg.ttf'
font_file = os.path.join(script_dir, font_path)
#Excelファイル名を記載
file_path = 'text_data_ja.xlsx'
#Excelファイルからデータを読み込む
df = pd.read_excel(file_path, 'data for run')
#独自ストップワード用データも読み込む
df2 = pd.read_excel(file_path, 'stopwords')
#リスト内の各要素をトークン化し、最後に半角スペース区切りで連結させる関数
#(この処理は列全体に対してではなくセル内の要素に対して実行されているイメージ)
def tokenize(text):
#空のリストを生成
tokens = []
#形態素解析結果をnodeに格納する
node = mecab.parseToNode(text)
#node内の要素をループする(node.surfaceの例、「明日」「は」「晴」「です」「。」)
while node:
if node.surface !='':
tokens.append(node.surface)
node = node.next
#node内の要素をスペースで連結する(例、明日 は 晴 です 。)
return ' '.join(tokens)
#指定列のリストで構成されたセル内にあたる各要素を関数処理し、処理済みの結果を新しく作成した'tokenized_text'列に反映させる。
df['tokenized_text'] = df['column1'].apply(tokenize) #★★★
#tokenized_text列の各セル同士もスペースで連結する
text_data = ' '.join([' '.join(tokens) for tokens in df['tokenized_text']])
#除外キーワードの設定
stop_words_list = df2['stopwords'].tolist()
#除外キーワードをループで除外
tokens = [word for word in text_data if not word in stop_words_list]
#wordcloud作成
wordcloud = WordCloud(width=1200, height=800, background_color='white', font_path=font_file).generate(' '.join(tokens))
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show(block=False)
input("press enter to exit..")

コメント