
以前仕事で使用したSeleniumというライブラリですが、今回使い方を思い出すためと、Googleスプレッドシートに反映するという新しい工程を加えることを目的とし、その内容を備忘録がてら残しておきたいと思います。
スクレイピング内容
コロナ禍の状況に合わせて随時更新される外務省海外安全ホームページから、各国の入国制限措置の内容をスクレイピングしていきたいと思います。
※今回ブラウザはChromeを使いますので、あらかじめChromeが入っているかご確認ください。
※OSはMac、環境はAnacondaを使用しています。


Seleniumのインストール
webブラウザ操作用ライブラリであるSeleniumをインストールします。
¥conda install seleniumChromeDriverのインストール
Chromeを操作するドライバをインストールします。
¥conda install python-chromedriver-binary読み込み確認
以下のコードを実行してみます。
読み込みが正しくできれいれば指定したURLが開きます。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import chromedriver_binary
#正しくインポートできていないとこの部分でエラーが出る
driver = webdriver.Chrome()
#今回スクレイピングする海外安全ホームページのサイトURL
driver.get('https://www.anzen.mofa.go.jp/covid19/pdfhistory_world.html')ちなみに私はこの部分で「Message: unknown error: cannot find Chrome binary」とエラーが出ました。通常Macのアプリケーションフォルダ内にあるGoogleChrome(/Applications/Google Chrome.app)が呼び出されますが、私の場合Chromeがダウンロードフォルダにありデフォルトで指定されていたパス内でChromeが見つからないことが原因でした。
Google Cloud Platformの設定
PythonからGoogleスプレッドシートにアクセスするための設定をします。
1.新規プロジェクトの作成
Google Cloud Platformにアクセスして、プロジェクトの選択をクリックします。
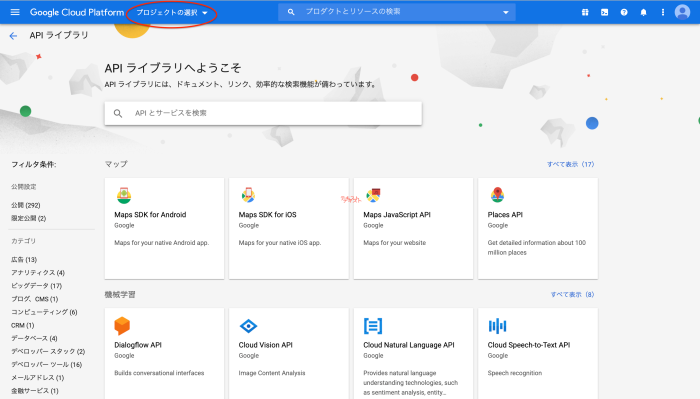
新しいプロジェクトをクリックします。
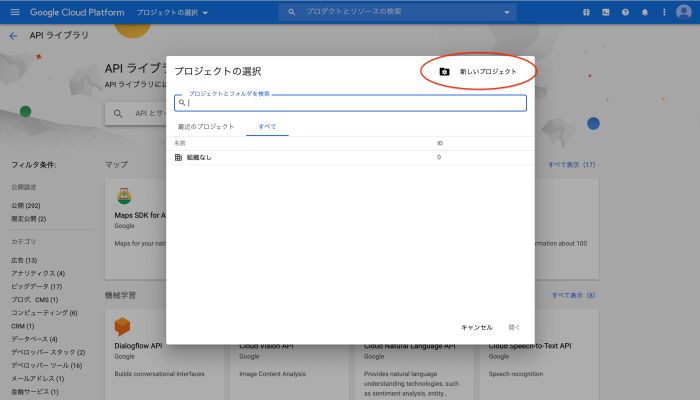
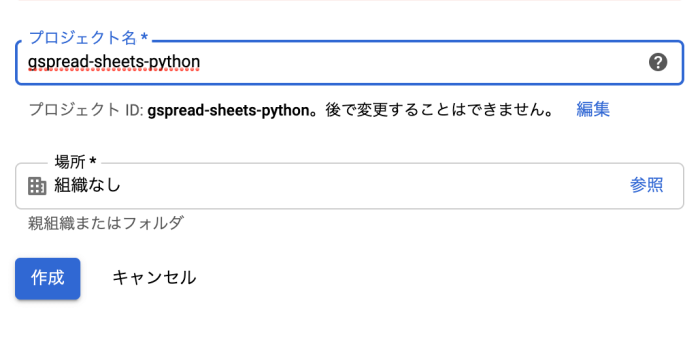
適当にプロジェクトタイトルを設定して作成をクリックします。
2.Google Drive APIを有効にする
PythonからGoogleドライブのツールにアクセスするためのAPIを有効にします。
「Google Drive API」を検索してクリックします。
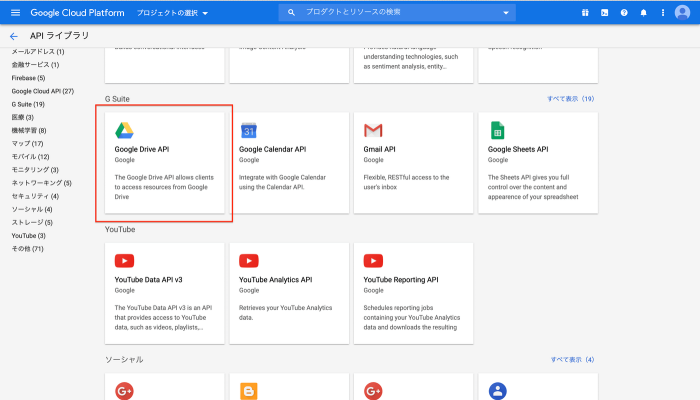
有効をクリックします。
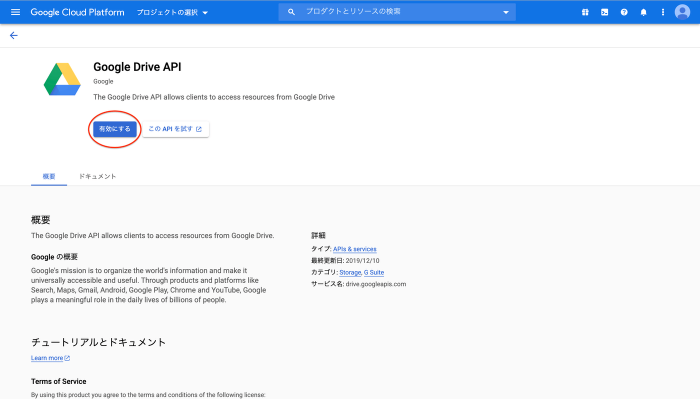
先ほど作成したプロジェクト名を選択します。
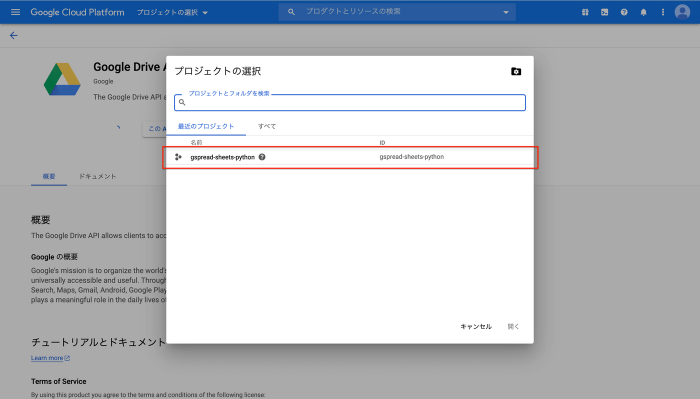
3.Google Sheets APIを有効にする
次はGoogleスプレッドシートを外部から操作するためのAPIを有効にします。
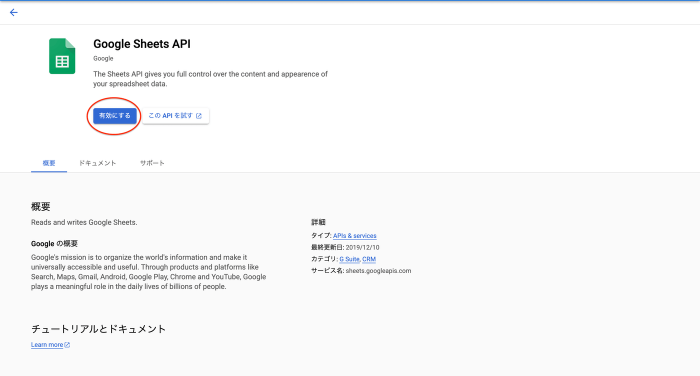
4.認証情報の設定
外部(Python)からアクセスする際に、認証に用いられる情報を取得します。
認証情報へ移動→認証情報を作成をクリック→サービスアカウントを選択します。
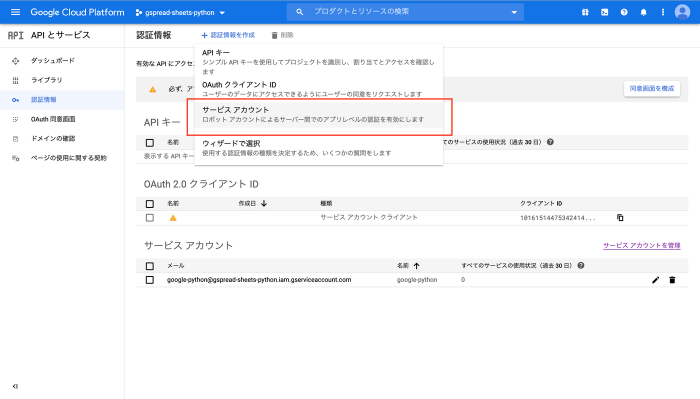
適当にサービスアカウント名を入力し、作成をクリックします。
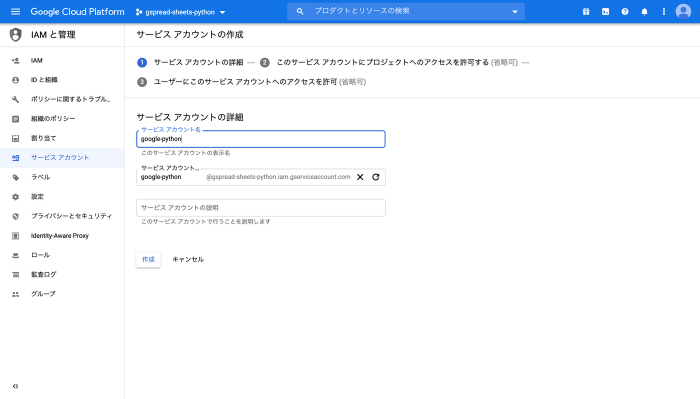
ロール(役割)では、プロジェクト→オーナーを選択します。
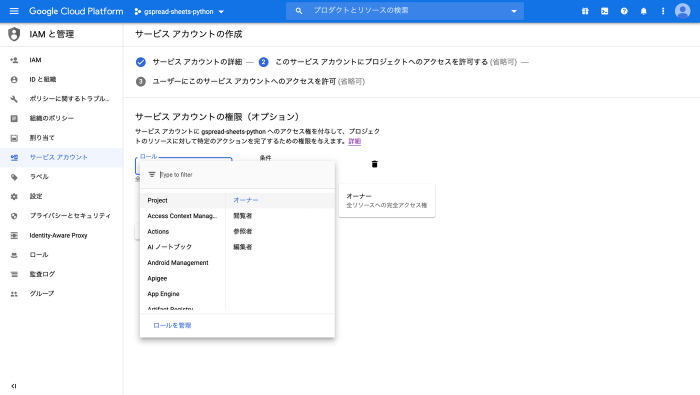
完了をクリックして終了します。
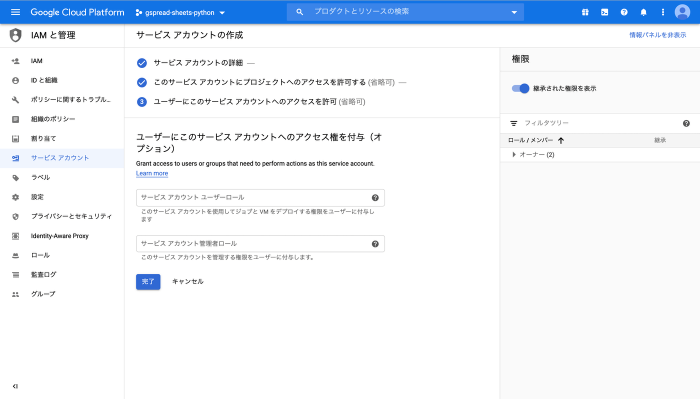
5.秘密鍵の作成
先ほど作成した認証情報の秘密鍵を作成します。先ほどのサービスアカウントをクリックします。
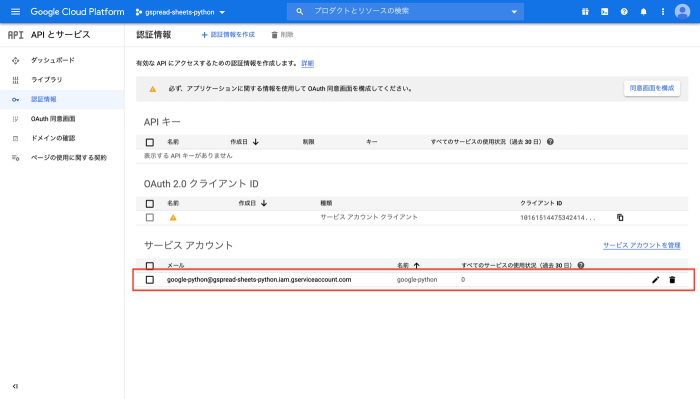
キーの新しい鍵を作成をクリックします。
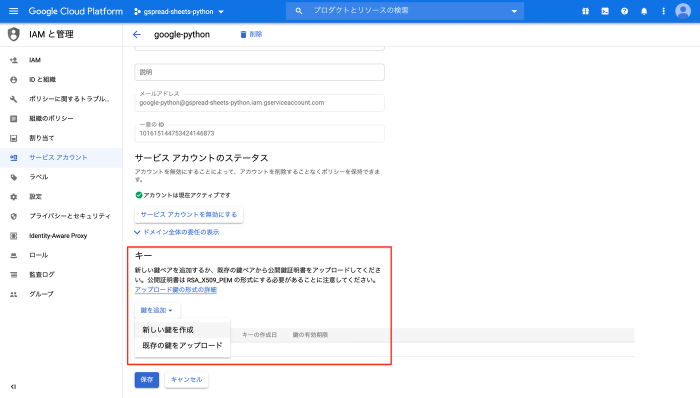
キータイプはjsonを選択し、作成をクリックします。
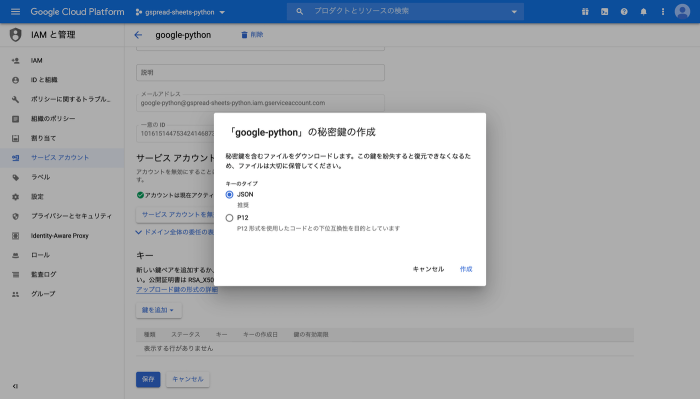
ダウンロードしたキーファイルはpython実行ファイルがあるディレクトリに格納します。
6.スプレッドシートの共有設定
先ほどダウンロードしたjsonファイル(キーファイル)を開き、“client_email”の横に書かれているアドレスをコピーします。
スプレッドシート右上の共有をクリックし、コピーしたアドレスをユーザーやグループと共有の箇所にペーストします。
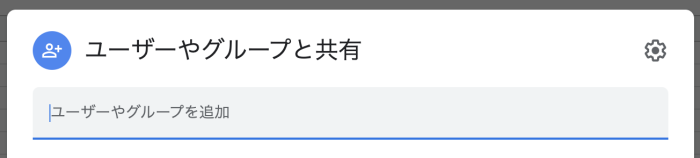
7.Googleスプレッドシートのkeyを取得
作成したスプレッドシート(gaimuscp)のリンクからキーと取得します。
https://docs.google.com/spreadsheets/d/xxxxxxxxxxxxxx/edit#gid=0ここでいう「xxxxxxxxxxxxxx」がキーになります。後で使用するので、この部分をコピーしてどこかに保管しておきましょう。
gspreadなどのインストール
スプレッドシートを操作するためのライブラリgspreadをインストールします。
¥pip install gspread続いて認証を通すためのライブラリoauth2clientをインストールします。
¥pip install oauth2client※追記:今現在oauth2clientは非推奨になっており、代わりとなるgoogle-authの使用についてもご検討ください。
プログラムを実行してみる
情報が欲しい国名を「赴任先リスト」シートにあらかじめ記載しておき、B列には検索の際に使用するHTMLのID名を記載します。ID名などはGoogleデベロッパーツール(右クリック→検証)であらかじめ確認しておきます。
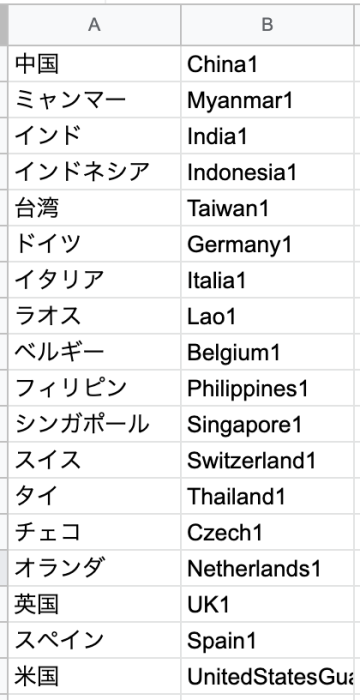
赴任先リストのIDに一致するテキストを取得し「info1」シートに反映するという処理内容を記載しています。(Pythonの記述方法にまだまだ改善の余地があると思っています…もっとスマートな書き方があれば是非アドバイス頂けたら嬉しいです)
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import chromedriver_binary
from oauth2client.service_account import ServiceAccountCredentials
import gspread
import os
driver = webdriver.Chrome()
driver.get('https://www.anzen.mofa.go.jp/covid19/pdfhistory_world.html')
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
# 5でダウンロードしたjsonファイル(キーファイル)名を指定
credentials = ServiceAccountCredentials.from_json_keyfile_name(
'gaimuscp2-9695fe220977.json', scope)
gc = gspread.authorize(credentials)
# 7で取得したキーを入力
SPREADSHEET_KEY = '1P9MEQOwGI9hcnopg2Zdq4OOidJV1Rh8-aaaaa'
wb = gc.open_by_key(SPREADSHEET_KEY)
ws_info = wb.worksheet('info1')
# 前回のデータをクリア
ws_info.clear()
ws_list = wb.worksheet('赴任先リスト')
values_list1 = ws_list.col_values(1)
values_list2 = ws_list.col_values(2)
ws_info.update_cell(1, 1, '国名')
ws_info.update_cell(1, 2, '1. 日本からの渡航者や日本人に対して入国制限措置をとっている国・地域')
counter = 1
for value1, value2 in zip(values_list1, values_list2):
counter += 1
# 国名をA列に反映
ws_info.update_cell(counter, 1, value1)
# テキストを反映(1セル50000文字を超えるとエラーが出るため文字数オーバーの場合はテキストの半分を次のセルに反映)
if len(driver.find_elements_by_id(value2)) > 0:
elem = driver.find_element_by_id(value2)
if len(elem.text) > 45000:
len_text = len(elem.text) / 2
elem1 = elem.text[:int(len_text)]
ws_info.update_cell(counter, 2, elem1)
counter += 1
elem2 = elem.text[int(len_text):]
ws_info.update_cell(counter, 2, elem2)
else:
ws_info.update_cell(counter, 2, elem.text)
driver.quit()
これを実行すると以下のようにテキストが反映されます。
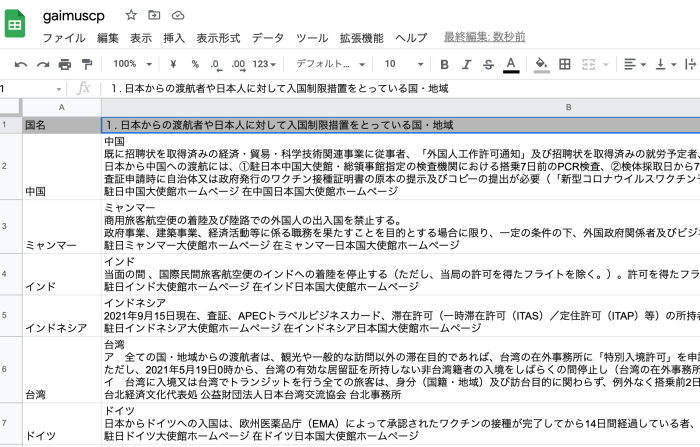
APIリクエストは1回の処理で最大100までという制限があるため、例えばこの場合だと国名が多かったり、取得したい項目が多いとこの制限に引っかかり「gspread.exceptions.APIError: {‘code’: 429, ‘message’: “Quota exceeded for quota metric ‘Write requests’ and limit ‘Write requests per minute per user’ of service ‘sheets.googleapis.com’ 〜」というようなエラーが出ることがあります。この場合の対策方法はいくつかあるようですが、私の場合手っ取り早く処理を2回に分けることで最後まで欲しい情報を取得できるようにしています。
今回は単純に、スクレイピングした情報をスプレッドシートに反映させるところまでですが、この情報を使用して更に機能を発展させることもできます。例えば、今回の例では「サイト上の更新日付が新たに更新されていたら、処理を実行し、内容が変更になった国を赤字で反映させて変更点を認識しやすくする」なども考えられるでしょうか。
応用方法については、情報をどのように使っていきたいかをベースに考えていきたいところです。

コメント